Ocr не может распознать конкретное изображение
Я пытаюсь сделать эти изображения ,  (8,0) признан Ocr
(8,0) признан Ocr
Я использую тессеракт, но я не против, если другой Ocr сделает это
1 ответ
Мы должны вызвать Тессеракт с опцией -psm <N> для настройки страницы:
0 = Orientation and script detection (OSD) only.
1 = Automatic page segmentation with OSD.
2 = Automatic page segmentation, but no OSD, or OCR.
3 = Fully automatic page segmentation, but no OSD. (Default)
4 = Assume a single column of text of variable sizes.
5 = Assume a single uniform block of vertically aligned text.
6 = Assume a single uniform block of text.
7 = Treat the image as a single text line.
8 = Treat the image as a single word.
9 = Treat the image as a single word in a circle.
10 = Treat the image as a single character.
Интересующие варианты 10 а также 6 в случае, если у нас есть только один символ в нашем источнике растрового изображения.
Отрисовывая источник серого изображения следующим образом
tesseract LO1v5.png -psm 6
мы получим правильный результат 8, но зеленый источник изображения - слишком сложная задача для тессеракта, который специализируется на целых текстах, а не на числах.
Улучшая качество ввода
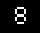
мы получим лучшие результаты при вызове tesseract в режиме распознавания одного символа:
tesseract sourceimage -psm 10
Это даст нам правильное предположение 8 но только почти правильное предположение B для 0 -образ.