BASH Script зависает после некоторой обработки в Ubuntu
Я запускаю приведенный ниже скрипт на сервере Red Hat, и он работает нормально и завершает работу. Файл, который я передаю, содержит полмиллиона строк (примерно 500000 строк), и поэтому (чтобы закончить его быстрее) я добавил '&' в конце блока while
Но теперь я настроил рабочий стол с 8 ГБ оперативной памяти, на котором работает Ubuntu 18.04, и тот же код запускает всего несколько тысяч строк, а затем зависает. Я немного прочитал об этом и увеличил лимит стека до безлимитного, и все равно он завис после 80000 строк или около того. Есть предложения о том, как мне оптимизировать код или настроить параметры моего ПК, чтобы всегда завершать работу?
while read -r CID60
do
{
OLT=$(echo "$CID60" | cut -d"|" -f5)
ONID=${OLT}:$(echo "$CID60" | cut -d, -f2 | sed 's/ //g ; s/).*|//')
echo $ONID,$(echo "$CID60" | cut -d"|" -f3) >> $localpath/CID_$logfile.csv
} &
done < $localpath/$CID7360
Входные данные:
202-00_MSRFKH00OL6:R1.S1.LT7.PON8.ASSN45| Unlocked|12-654-0330|Up|202-00_MSRFKH00OL6|P282018767.C2028 ( network, R1.S1.LT7.PON8.ONT81.SERV1 )|
202-00_MSRFKH00OL6:R1.S1.LT7.PON8.ASSN46| Unlocked|12-654-0330|Down|202-00_MSRFKH00OL6|P282017856.C881 ( local, R1.S1.LT7.PON8.ONT81.C1.P1 )|
202-00_MSRFKH00OL6:R1.S1.LT7.PON8.ASSN52| Unlocked|12-664-1186|Up|202-00_MSRFKH00OL6|P282012623.C2028 ( network, R1.S1.LT7.PON8.ONT75.SERV1 )|
выход:
202-00_MSRFKH00OL6:R1.S1.LT7.PON8.ONT81.SERV1,12-654-0330
202-00_MSRFKH00OL6:R1.S1.LT7.PON8.ONT81.C1.P1,12-654-0330
202-00_MSRFKH00OL6:R1.S1.LT7.PON8.ONT75.SERV1,12-664-1186
мой интерес представляет 5-й столбец (разделенный с трубкой |) соединяется с частью последнего столбца, а затем с третьим столбцом
5 ответов
Perl решение
Этот скрипт ничего не делает параллельно, но довольно быстрый. Сохранить как filter.pl (или любое другое имя, которое вы предпочитаете) и сделайте его исполняемым.
#!/usr/bin/env perl
use strict;
use warnings;
while( <> ) {
if ( /^(?:[^|]+\|){2}([^|]+)\|[^|]+\|([^|]+)\|[^,]+,\s*(\S+)/ ) {
print "$2:$3,$1\n";
}
}
Я копировал ваши образцы данных, пока не получил 1572 864 строки, а затем запустил их следующим образом:
me@ubuntu:~> time ./filter.pl < input.txt > output.txt
real 0m3,603s
user 0m3,487s
sys 0m0,100s
me@ubuntu:~> tail -3 output.txt
202-00_MSRFKH00OL6:R1.S1.LT7.PON8.ONT81.SERV1,12-654-0330
202-00_MSRFKH00OL6:R1.S1.LT7.PON8.ONT81.C1.P1,12-654-0330
202-00_MSRFKH00OL6:R1.S1.LT7.PON8.ONT75.SERV1,12-664-1186
Если вы предпочитаете однострочники, сделайте:
perl -lne 'print "$2:$3,$1" if /^(?:[^|]+\|){2}([^|]+)\|[^|]+\|([^|]+)\|[^,]+,\s*(\S+)/;' < input.txt > output.txt
Чистый раствор sed:
sed -r 's/^[^|]+\|[^|]+\|([^|]+)\|[^|]+\|([^|]+)\|.+\( .+, ([^ ]+).+/\2:\3,\1/' <in.dat >out.dat
doit() {
# Hattip to @sudodus
tr ' ' '|' |
tr -s '|' '|' |
cut -d '|' -f 3,5,9
}
export -f doit
parallel -k --pipepart --block -1 -a input.txt doit > output.txt
-kсохраняйте порядок, поэтому первая / последняя строка ввода также будет первой / последней строкой вывода--pipepartразбивает файл на лету--block -1в 1 чанк на поток процессора-a input.txtфайл для разделенияdoitкоманда (или функция bash) для вызова
Быстро parallel (желтая) версия превосходит tr (черный) около 200 МБ в моей системе (секунды против МБ):
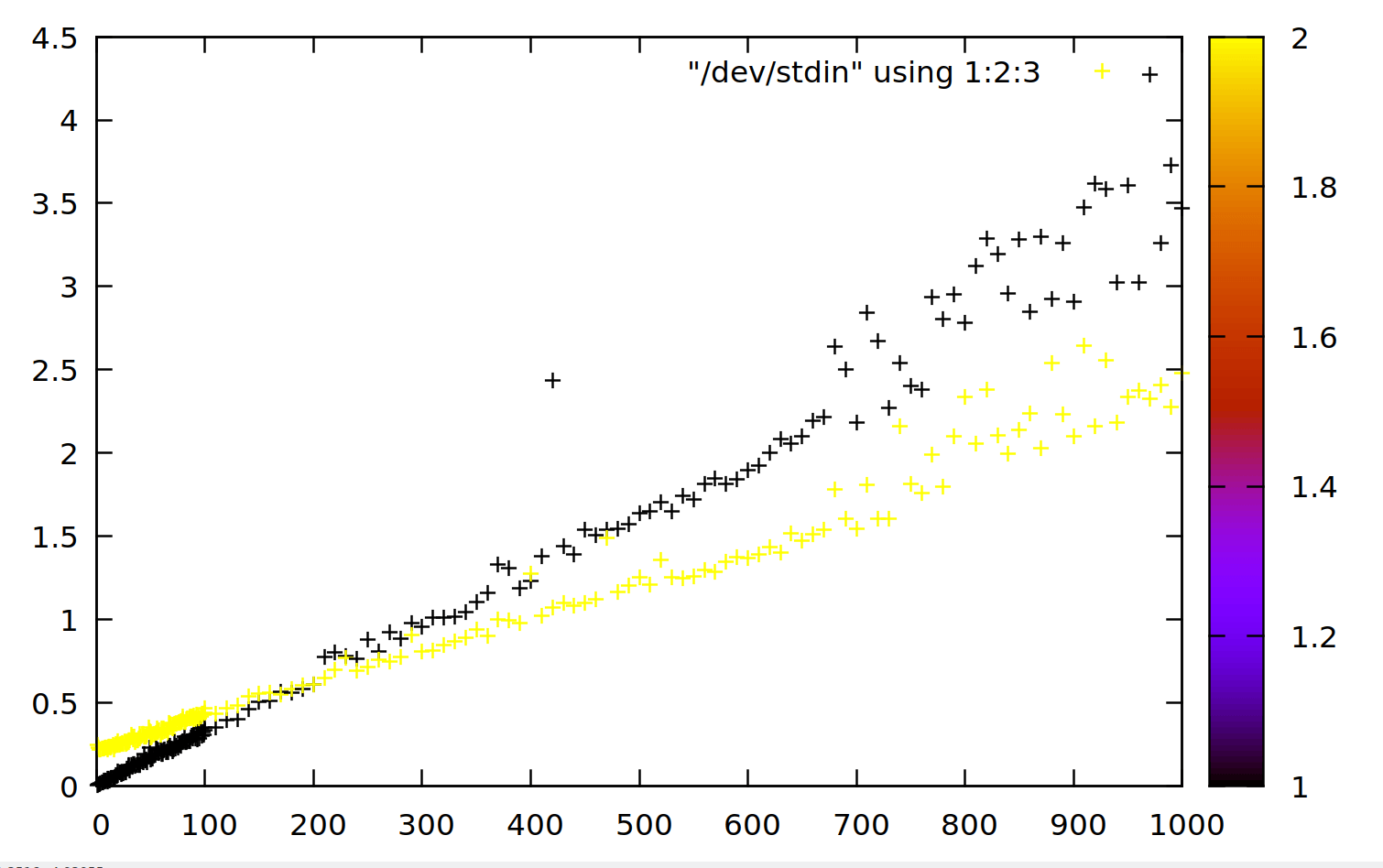
Oneliners от меня и других лиц, а также некоторые сценарии проверены
Если порядок элементов и разделителей может отличаться от того, который вы указали в вопросе, я подумал, что это сделает следующая строка:
< input tr ' ' '|' | cut -d '|' -f 4,6,10 > output
но в комментарии вы написали, что вам нужен именно указанный формат.
Я добавил решение с помощью awk, что примерно соответствует решению PerlDuck с perl, Смотрите конец этого ответа.
< input awk '{gsub("\\|"," "); print $5 ":" $9 "," $3}' > output
Тестирование oneliners и маленьких скриптов
Тест проводился на моем компьютере с Lubuntu 18.04.1 LTS, процессорами 2*2 и 4 ГБ ОЗУ.
Я сделал огромный infile "удвоив 20 раз" из вашей демонстрации input (1572864 строки), поэтому некоторый запас для ваших 500000 строк,
Oneliner с cut а также sed:
$ < infile cut -d '|' -f 3,5,6 | sed -e 's/|[A-Z].*, /|/' -e 's/ )$//' > outfile
$ wc -l infile
1572864 infile
$ wc -l outfile
1572864 outfile
$ tail outfile
12-664-1186|202-00_MSRFKH00OL6|R1.S1.LT7.PON8.ONT75.SERV1
12-654-0330|202-00_MSRFKH00OL6|R1.S1.LT7.PON8.ONT81.SERV1
12-654-0330|202-00_MSRFKH00OL6|R1.S1.LT7.PON8.ONT81.C1.P1
12-664-1186|202-00_MSRFKH00OL6|R1.S1.LT7.PON8.ONT75.SERV1
12-654-0330|202-00_MSRFKH00OL6|R1.S1.LT7.PON8.ONT81.SERV1
12-654-0330|202-00_MSRFKH00OL6|R1.S1.LT7.PON8.ONT81.C1.P1
12-664-1186|202-00_MSRFKH00OL6|R1.S1.LT7.PON8.ONT75.SERV1
12-654-0330|202-00_MSRFKH00OL6|R1.S1.LT7.PON8.ONT81.SERV1
12-654-0330|202-00_MSRFKH00OL6|R1.S1.LT7.PON8.ONT81.C1.P1
12-664-1186|202-00_MSRFKH00OL6|R1.S1.LT7.PON8.ONT75.SERV1
тайминг
Можно ожидать, что чистый sed решение будет быстрее, но я думаю, что изменение порядка данных замедляет его, так что cut а также sed решение быстрее. Оба решения работают без проблем на моем компьютере.
Oneliner с cut а также sed :
$ time < infile cut -d '|' -f 3,5,6 | sed -e 's/|[A-Z].*, /|/' -e 's/ )$//' > outfile
real 0m8,132s
user 0m8,633s
sys 0m0,617s
Чистый sed онелинер ксеноидом:
$ time sed -r 's/^[^|]+\|[^|]+\|([^|]+)\|[^|]+\|([^|]+)\|.+\( .+, ([^ ]+).+/\2:\3,\1/' <infile > outfile-sed
real 1m8,686s
user 1m8,259s
sys 0m0,344s
python скрипт, использующий регулярное выражение с не жадными совпадениями по xeniod:
#!/usr/bin/python
import sys,re
pattern=re.compile(r'^[^|]+?\|[^|]+?\|([^|]+?)\|[^|]+?\|([^|]+?)\|[^,]+?, (.+) \)\|$')
for line in sys.stdin:
match=pattern.match(line)
if match:
print(match.group(2)+':'+match.group(3)+','+match.group(1))
$ time < infile ./python-ng > outfile.pyng
real 0m8,055s
user 0m7,359s
sys 0m0,300s
$ python --version
Python 2.7.15rc1
perl Oneliner от PerlDuck работает быстрее, чем предыдущие oneliners:
$ time perl -lne 'print "$2:$3,$1" if /^(?:[^|]+\|){2}([^|]+)\|[^|]+\|([^|]+)\|[^,]+,\s*(\S+)/;' < infile > outfile.perl
real 0m5,929s
user 0m5,339s
sys 0m0,256s
Oneliner с tr а также cut с tr -s команда:
я использовал tr преобразовать пробелы во входном файле в символы конвейера, а затем cut мог бы сделать все это без sed, Как вы видете, tr намного быстрее чем sed, tr -s Команда удаляет двойные каналы во входных данных, что является хорошей идеей, особенно если во входном файле могут быть повторяющиеся пробелы или каналы. Это не стоит дорого.
$ time < infile tr ' ' '|' | tr -s '|' '|' | cut -d '|' -f 3,5,9 > outfile-tr-cut
real 0m1,277s
user 0m1,781s
sys 0m0,925s
Oneliner с tr а также cut без tr -s Команда, самая быстрая на данный момент:
time < infile tr ' ' '|' | cut -d '|' -f 4,6,10 > outfile-tr-cut
real 0m1,199s
user 0m1,020s
sys 0m0,618s
$ tail outfile-tr-cut
12-664-1186|202-00_MSRFKH00OL6|R1.S1.LT7.PON8.ONT75.SERV1
12-654-0330|202-00_MSRFKH00OL6|R1.S1.LT7.PON8.ONT81.SERV1
12-654-0330|202-00_MSRFKH00OL6|R1.S1.LT7.PON8.ONT81.C1.P1
12-664-1186|202-00_MSRFKH00OL6|R1.S1.LT7.PON8.ONT75.SERV1
12-654-0330|202-00_MSRFKH00OL6|R1.S1.LT7.PON8.ONT81.SERV1
12-654-0330|202-00_MSRFKH00OL6|R1.S1.LT7.PON8.ONT81.C1.P1
12-664-1186|202-00_MSRFKH00OL6|R1.S1.LT7.PON8.ONT75.SERV1
12-654-0330|202-00_MSRFKH00OL6|R1.S1.LT7.PON8.ONT81.SERV1
12-654-0330|202-00_MSRFKH00OL6|R1.S1.LT7.PON8.ONT81.C1.P1
12-664-1186|202-00_MSRFKH00OL6|R1.S1.LT7.PON8.ONT75.SERV1
Oneliner с awk , быстрый, но не самый быстрый,
< input awk '{gsub("\\|"," "); print $5 ":" $9 "," $3}' > output
$ time < infile awk '{gsub("\\|"," "); print $5 ":" $9 "," $3}' > outfile.awk
real 0m5,091s
user 0m4,724s
sys 0m0,365s
awk с parallel реализованный в соответствии с Ole Tange сокращает в реальном времени с 5 секунд до 2 секунд:
#!/bin/bash
doit() {
awk '{gsub("\\|"," "); print $5 ":" $9 "," $3}'
}
export -f doit
parallel -k --pipepart --block -1 -a infile doit > outfile.parallel-awk
$ time ./parallel-awk
# Academic tradition requires you to cite works you base your article on.
# When using programs that use GNU Parallel to process data for publication
#please cite:
# O. Tange (2011): GNU Parallel - The Command-Line Power Tool,
# ;login: The USENIX Magazine, February 2011:42-47.
# This helps funding further development; AND IT WON'T COST YOU A CENT.
#If you pay 10000 EUR you should feel free to use GNU Parallel without citing.
# To silence this citation notice: run 'parallel --citation'.
real 0m1,994s
user 0m5,015s
sys 0m0,984s
Мы можем ожидать, что преимущество с parallel будет увеличиваться с увеличением размера входного файла, как описано диаграммой в ответе Олы Танге на этот вопрос.
Сводка скорости: "реальное" время в соответствии с time округляется до 1 десятичного знака
1m 8.7s - sed
8.1s - cut & sed
7.4s - python
5.9s - perl
5.1s - awk
2.0s - parallel & awk
1.2s - tr & cut
Наконец, я отмечаю, что sed, python, perl, awk а также { parallel & awk } создать выходной файл с заданным форматом.
$ tail outfile.awk
202-00_MSRFKH00OL6:R1.S1.LT7.PON8.ONT75.SERV1,12-664-1186
202-00_MSRFKH00OL6:R1.S1.LT7.PON8.ONT81.SERV1,12-654-0330
202-00_MSRFKH00OL6:R1.S1.LT7.PON8.ONT81.C1.P1,12-654-0330
202-00_MSRFKH00OL6:R1.S1.LT7.PON8.ONT75.SERV1,12-664-1186
202-00_MSRFKH00OL6:R1.S1.LT7.PON8.ONT81.SERV1,12-654-0330
202-00_MSRFKH00OL6:R1.S1.LT7.PON8.ONT81.C1.P1,12-654-0330
202-00_MSRFKH00OL6:R1.S1.LT7.PON8.ONT75.SERV1,12-664-1186
202-00_MSRFKH00OL6:R1.S1.LT7.PON8.ONT81.SERV1,12-654-0330
202-00_MSRFKH00OL6:R1.S1.LT7.PON8.ONT81.C1.P1,12-654-0330
202-00_MSRFKH00OL6:R1.S1.LT7.PON8.ONT75.SERV1,12-664-1186
питон
import sys,re
pattern=re.compile(r'^.+\|.+\|(.+)\|.+\|(.+)\|.+, (.+) \)\|$')
for line in sys.stdin:
match=pattern.match(line)
if match:
print(match.group(2)+':'+match.group(3)+','+match.group(1))
(работает как с Python2, так и с Python3)
Использование регулярных выражений с не жадными совпадениями в 4 раза быстрее (избегает обратного отслеживания?) И ставит python в один ряд с методом cut/sed (python2 немного быстрее, чем python3)
import sys,re
pattern=re.compile(r'^[^|]+?\|[^|]+?\|([^|]+?)\|[^|]+?\|([^|]+?)\|[^,]+?, (.+) \)\|$')
for line in sys.stdin:
match=pattern.match(line)
if match:
print(match.group(2)+':'+match.group(3)+','+match.group(1))