Имеют ли расширения файлов какое-либо назначение (для операционной системы)?
Linux определяет тип файла с помощью кода в заголовке файла. Это не зависит от расширений файлов, позволяющих узнать, какое программное обеспечение следует использовать для открытия файла.
Это то, что я помню из моего образования. Пожалуйста, поправьте меня, если я ошибаюсь!
Недавно немного поработал с системами Ubuntu: в системах я вижу много файлов с такими расширениями, как .sh, .txt, .o, .c
Теперь мне интересно: эти расширения предназначены только для людей? Чтобы понять, что это за файл?
Или у них тоже есть какая-то цель для операционной системы?
7 ответов
Linux определяет тип файла с помощью кода в заголовке файла. Это не зависит от расширений файлов, чтобы знать, с помощью программного обеспечения использовать для открытия файла.
Это то, что я помню из моего образования. Пожалуйста, поправьте меня, если я ошибаюсь!
- правильно помнил.
Эти расширения предназначены только для людей?
- Да, но с
Когда вы взаимодействуете с другими операционными системами, которые зависят от того, какими расширениями они являются, разумнее использовать их.
В Windows открывающее программное обеспечение прикреплено к расширениям.
Открыть текстовый файл с именем "file" в Windows сложнее, чем открыть тот же файл с именем "file.txt" (вам нужно будет переключить диалог открытия файла из *.txt в *.* каждый раз). То же самое касается TAB и текстовых файлов, разделенных точкой с запятой. То же самое касается импорта и экспорта электронной почты (расширение.mbox).
В частности, когда вы пишете программное обеспечение. Открытие файла с именем "software1", который является файлом HTML, и "software2", который является файлом JavaScript, становится более сложным по сравнению с "software.html" и "software.js".
Если в Linux есть система, в которой важны расширения файлов, я бы назвал это ошибкой. Когда программное обеспечение зависит от расширений файлов, это можно использовать. Мы используем директиву интерпретатора, чтобы определить, что это за файл ("первые два байта в файле могут быть символами"#!", Которые составляют магическое число" (шестнадцатеричные 23 и 21, значения ASCII "#" и "!") часто упоминается как Шебанг").
Самой известной проблемой с расширениями файлов была LOVE-LETTER-FOR-YOU.TXT.vbs в Windows. Это визуальный базовый скрипт, который отображается в проводнике как текстовый файл.
В Ubuntu, когда вы запускаете файл из Nautilus, вы получаете предупреждение о том, что он собирается делать. Выполнение скрипта из Nautilus, где он хочет запустить какое-то программное обеспечение, где предполагается открыть gEdit, является очевидной проблемой, и мы получаем предупреждение об этом.
В командной строке, когда вы выполняете что-то, вы можете визуально увидеть, что такое расширение. Если это заканчивается на.vbs, я начинаю подозревать (не то, что.vbs исполняемый в Linux. По крайней мере, без особых усилий;)).
Здесь нет 100% черного или белого ответа.
Обычно Linux не полагается на имена файлов (и расширения файлов, то есть часть имени файла после обычно последнего периода), а вместо этого определяет тип файла, изучая первые несколько байтов его содержимого и сравнивая его со списком известных магических чисел.,
Например, все файлы растровых изображений (обычно с расширением имени .bmp) должен начинаться с букв BM в их первых двух байтах. Скрипты в большинстве языков сценариев, таких как Bash, Python, Perl, AWK и т. Д. (В основном все, что обрабатывает строки, начинающиеся с # в качестве комментария) может содержать как Шебанг, как #!/bin/bash как первая строка Этот специальный комментарий сообщает системе, с помощью какого приложения открывать файл.
Поэтому обычно операционная система полагается на содержимое файла, а не на его имя, чтобы определить тип файла, но заявить, что расширения файлов никогда не нужны в Linux, - это только половина правды.
Приложения могут, конечно, осуществлять свои проверки файлов по своему усмотрению, включая проверку имени и расширения файла. Примером является Глаз Гнома (eogстандартное средство просмотра изображений), которое определяет формат изображения по расширению файла и выдает ошибку, если оно не соответствует содержимому. Будь то ошибка или особенность, можно обсудить...
Однако даже некоторые части операционной системы зависят от расширений имен файлов, например, при разборе исходных файлов программного обеспечения в /etc/apt/sources.list.d/ - только файлы с *.list расширение анализируется, все остальные игнорируются. Возможно, он в основном используется не для определения типа файла, а для включения / отключения анализа некоторых файлов, но это все еще расширение файла, которое влияет на то, как система обрабатывает файл.
И, конечно же, пользователь извлекает наибольшую выгоду из расширений файлов, поскольку это делает тип файла очевидным, а также позволяет использовать несколько файлов с одинаковым базовым именем и разными расширениями, такими как site.html, site.php, site.js, site.css и т.д. Недостатком является, конечно, то, что расширение файла и фактический тип файла / содержание не обязательно должны совпадать.
Кроме того, это необходимо для межплатформенного взаимодействия, например, Windows не будет знать, что делать с readme файл, но только readme.txt,
Я хотел бы использовать другой подход к этому из других ответов и оспорить идею о том, что "Linux" или "Windows" имеют какое-либо отношение к этому (терпите меня).
Понятие расширения файла может быть просто выражено как "соглашение для идентификации типа файла на основе части его имени". Другие общие соглашения для определения типа файла сравнивают его содержимое с базой данных известных сигнатур (подход "магического числа") и сохраняют его как дополнительный атрибут в файловой системе (подход, используемый в оригинальной MacOS),
Поскольку каждый файл в системе Windows или Linux имеет как имя, так и содержимое, процессы, которые хотят знать тип файла, могут использовать подходы "расширение" или "магическое число" по своему усмотрению. Подход метаданных обычно недоступен, так как в большинстве файловых систем нет стандартного места для этого атрибута.
В Windows существует сильная традиция использовать расширение файла в качестве основного средства идентификации файла; Наиболее заметно, что графический файловый браузер (File Manager в Windows 3.1 и Explorer в современной Windows) использует его, когда вы дважды щелкаете файл, чтобы определить, какое приложение запустить. В Linux (и, в более общем случае, в системах на основе Unix), существует больше традиций для проверки содержимого; в частности, ядро смотрит на начало файла, который выполняется непосредственно, чтобы определить, как его запустить; Файлы сценариев могут указывать на использование интерпретатора, начиная с #! следуют пути к переводчику.
Эти традиции влияют на дизайн пользовательского интерфейса программ, написанных для каждой системы, но есть множество исключений, потому что у каждого подхода есть свои плюсы и минусы в разных ситуациях. Причины использования расширений файлов вместо изучения содержимого включают в себя:
- проверка содержимого файла довольно затратна по сравнению с проверкой имен файлов; так, например, "найти все файлы с именем *.conf" будет намного быстрее, чем "найти все файлы, первая строка которых соответствует этой подписи"
- содержимое файла может быть неоднозначным; многие форматы файлов на самом деле представляют собой просто текстовые файлы, обрабатываемые особым образом, многие другие представляют собой специально структурированные zip-файлы, и определение точных сигнатур для них может быть сложным
- файл действительно может быть действительным как более одного типа; HTML-файл также может быть допустимым XML, ZIP-файл и GIF, объединенные вместе, остаются действительными для обоих форматов.
- совпадение магических чисел может привести к ложным срабатываниям; формат файла без заголовка может начинаться с байта "GIF89a" и быть неверно идентифицирован как изображение GIF
- переименование файла может быть удобным способом пометить его как "отключенный"; например, изменение "foo.conf" на "foo.conf ~" для указания на то, что резервная копия проще, чем редактирование файла, чтобы закомментировать все его директивы, и более удобно, чем перемещение его из каталога с автозагрузкой; аналогично, переименование файла.php в.txt скажет Apache, чтобы он служил своим источником в виде простого текста, а не передавал его движку PHP.
Примеры программ Linux, которые используют имена файлов по умолчанию (но могут иметь другие режимы):
- gzip и gunzip имеют специальную обработку любого файла, оканчивающегося на ".gz"
- gcc будет обрабатывать файлы ".c" как C, а ".cc" или ".C" как C++
Как упоминалось другими, в Linux используется метод директивы интерпретатора (сохранение некоторых метаданных в файле в виде заголовка или магического числа, чтобы правильному интерпретатору можно было прочитать его), а не метод ассоциации расширения имени файла, используемый Windows.
Это означает, что вы можете создать файл с почти любым именем, которое вам нравится... с несколькими исключениями
тем не мение
Я хотел бы добавить слово предостережения.
Если в вашей системе есть несколько файлов из системы, в которой используется сопоставление имен файлов, файлы могут не иметь этих магических чисел или заголовков. Расширения имен файлов используются для идентификации этих файлов приложениями, которые могут их прочитать, и вы можете столкнуться с некоторыми неожиданными последствиями, если переименовать такие файлы. Например:
Если вы переименуете файл My Novel.doc в My-Novel, Libreoffice по-прежнему сможет открыть его, но он откроется как "Без названия", и вам придется снова назвать его, чтобы сохранить его (Libreoffice добавляет расширение по умолчанию, поэтому у вас будет два файла My-Novel а также My-Novel.odtчто может раздражать)
Если серьезно, если вы переименуете файл My Spreadsheet.xlsx в My-Spreadsheet, попробуйте открыть его с помощью xdg-open My-Spreadsheet вы получите это (потому что это на самом деле сжатый файл):
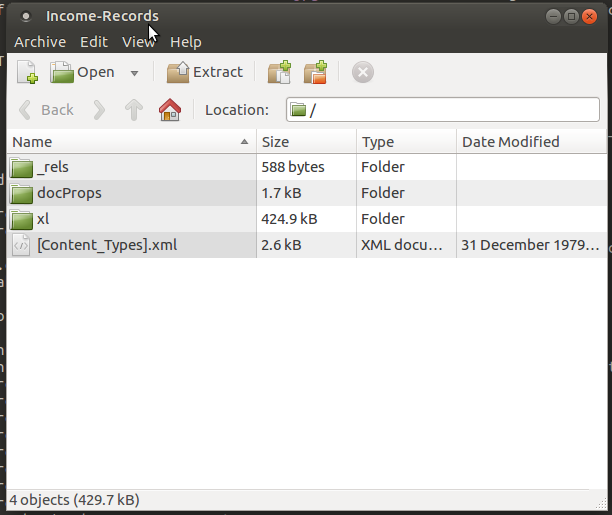
И если вы переименуете файл My Spreadsheet.xls в My-Spreadsheet, когда ты xdg-open My-Spreadsheet вы получаете сообщение об ошибке
Ошибка открытия местоположения: ни одно приложение не зарегистрировано для обработки этого файла
(Хотя в обоих случаях это работает нормально, если вы soffice My-Spreadsheet)
Если вы затем переименуете файл без расширений в My-Spreadsheet.ods с mv и попробуйте открыть его, вы получите это:
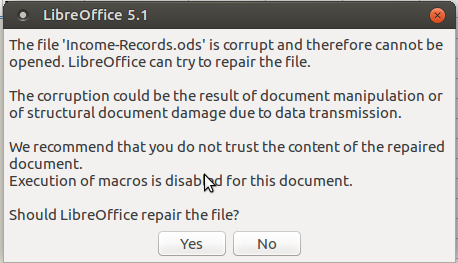
(ремонт не удается)
И вам придется снова установить оригинальное расширение, чтобы правильно открыть файл (затем вы можете преобразовать формат, если хотите)
TL; DR:
Если у вас есть неродные файлы с расширениями имени, не удаляйте расширения, если все будет в порядке!
На самом деле, некоторые технологии полагаются на расширения файлов, поэтому, если вы используете эти технологии в Ubuntu, вам также придется полагаться на расширения. Несколько примеров:
gccиспользует расширения, чтобы различать файлы C и C++. Без расширения их практически невозможно дифференцировать (представьте себе файл C++ без классов).- много файлов (
docx,jar,apk) являются просто особо структурированными ZIP-архивами. Хотя вы обычно можете вывести тип из содержимого, это не всегда возможно (например, манифест Java не является обязательным вjarфайлы).
Не использовать расширения файлов в таких случаях будет возможно только с помощью хакерских обходных путей и, вероятно, будет очень подвержен ошибкам.
Ваше первое предположение верно: расширения в Linux не имеют значения и полезны только для людей (и других не-Unix-подобных ОС, которые заботятся о расширениях). Тип файла определяется первыми 32 битами данных в файле, которые известны как магическое число. Вот почему сценарии оболочки нужны #! строка - сообщить операционной системе, какой интерпретатор вызывать. Без него сценарий оболочки - это просто текстовый файл.
Что касается файловых менеджеров, они хотят знать расширения некоторых файлов, такие как .desktop файлы, которые в основном совпадают с версией ярлыков Windows, но имеют больше возможностей. Но что касается ОС, она должна знать, что находится в файле, а не в его названии.
Это слишком большой ответ на комментарий.
Имейте в виду, что даже "расширение" имеет много, если разные значения.
То, о чем вы говорите, похоже, состоит из 3 букв после. DOS сделал формат 8.3 по-настоящему популярным, и в Windows по сей день используется часть.3.
В Linux есть много файлов, таких как.conf или.list или.d или.c, которые имеют значение, но на самом деле не являются расширениями в смысле 8.3. Например, Apache ищет директиву конфигурации в /etc/apache2/sites-enabled/website.conf. В то время как система использует MIME-типы и заголовки содержимого, а не то, чтобы определить, что это текстовый файл, Apache (по умолчанию) по-прежнему не собирается загружать его без окончания в.conf.
.c еще один замечательный. Да, это текстовый файл, но gcc зависит от main.c, который становится main.o и, наконец, main (после связывания). Система ни разу не использует расширение.c,.o или no, чтобы иметь какое-либо значение для содержимого, но для содержимого после. действительно имеет какое-то значение. Вы, вероятно, настроите свой SCM на игнорирование main.o и main.
Дело в том, что расширения не используются так, как в окнах. Ядро не выполнит файл.txt, потому что вы удалите часть имени.txt. Также очень рад выполнить файл.txt, если установлено разрешение на выполнение. При этом, они имеют значение, и все еще используются на "компьютерном уровне" для многих вещей.